第 1 回
ISO 42001発行の背景
コラム1 ISO 42001の発行の背景 – AIの進化の歴史とリスク
AI関連の技術は日々進歩しており、AIを利用する機会やさまざまなAI利用の可能性は拡大の一途をたどっている。特に、近年台頭してきた対話型の生成AIによって、多くの人々がその便利なAIとの対話によって、AIをより容易にさまざまな用途で活用できるように進化させている。
AIはArtificial Intelligence(人工知能)の略となり、人の思考と同じようなプロセスで動作するコンピュータープログラムや、そのプログラムを利用したシステムを指す。なお、AIの国際規格である、ISO/IEC 22989:2022(情報技術-人工知能-人工知能の概念及び用語)では、人間が定義した所与の目標の集合に対して、コンテンツ、予測、推奨、意思決定などの出力を生成する工学的システムと定義している。
AIは、2000年代以降に飛躍的に進化を遂げ、ディープラーニングなどによる、音声認識、画像認識、翻訳(自然言語処理)に活用されるようになり、特定の分野に特化し、推測・予測、提案や意思決定を行うことができるものが誕生した。また、2020年以降、ICTの技術的な進歩により、特定の分野のみに特化したAIではなく、汎用的なAIが誕生し、その結果、推測・予測、提案や意思決定にとどまらず、文章や画像などを作成してくれる、生成AIが普及するようになった。
第一次AIブーム(1950年代~1960年代)
この時期の研究者たちは人間の思考を模倣することを目指し、探索アルゴリズムや論理的推論の開発に注力した。 しかし、当時のコンピューターの性能は限られており、複雑な問題を解決するには不十分であった。 また、現実世界の曖昧さや不確実性を扱うことが難しく、期待された成果を上げることができなかったといえる。
第三次AIブーム(2000年代~ 2010年代)
2000年代に入り、インターネットの普及とコンピューターの性能向上により、大量のデータ(ビッグデータ)の収集と処理が可能になった。 これに伴い、機械学習、特にディープラーニングが注目を集めました。なお、ディープラーニングとは、複雑なパターン認識を可能とする機械学習の手法を指す。
ディープラーニングは、多層のニューラルネットワーク(脳の神経回路を模して造られた構造)を用いて、画像認識や音声認識、人が会話で使用する自然言語の処理などの分野で高い精度を実現した。 これにより、AIは複雑な問題にも対応できるようになり、第三次AIブームが到来した。なお、第三次AIブームは廃れることなく、更なる技術の飛躍を経て第四次AIブームへと移行した。
第二次AIブーム(1980年代)
1980年代に入り、AI研究は再び注目を集めた。この時期の中心は、特定の専門知識を持つエキスパートシステムの開発であった。なお、エキスパートシステムとは、専門家の知識をルールベースでプログラムに組み込むことで、特定の問題解決を可能にした。 しかし、知識の収集と更新には多大な労力が必要であり、また、未知の状況や複雑な問題には対応できないという限界があった。
第四次AIブーム(2020年代~)
近年は、自律的にコンテンツを生成する生成AIへと進化している。 特に、大規模言語モデル(LLM)の登場により、テキスト、画像、音声、動画など多様なコンテンツの生成が可能となった。なお、 生成AIは、再トレーニングを必要とせず、プロンプト(指示)に応じて柔軟に出力を生成することができることから、クリエイティブな分野や業務効率化など、さまざまな領域での活用が進んでいる。
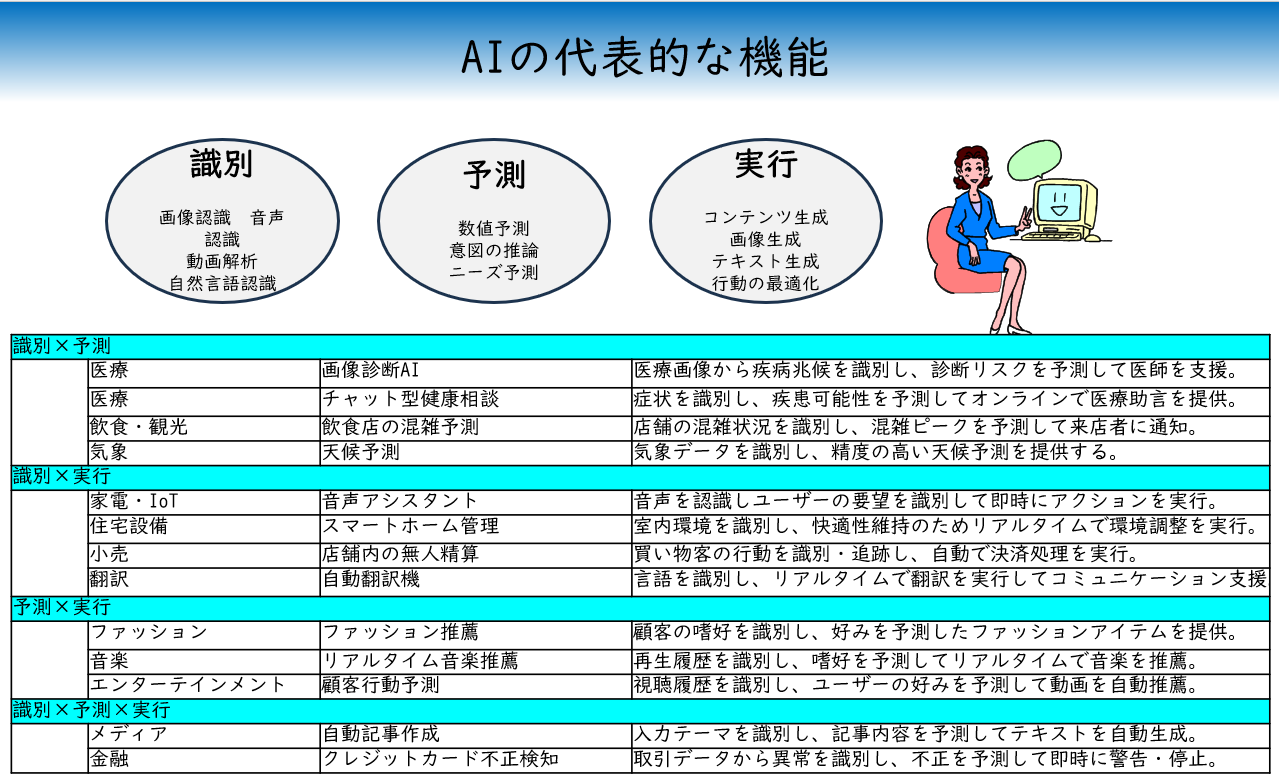
近年になり、AIの活用範囲は更に広がっている。その背景にはAIが複雑なデータを適切に“識別”し、そこからパターンを学んで“予測”を行い、更に利用者の意図に沿って“実行”まで担えるようになった技術的進歩がある。
なお、AIの主要な3つの機能である、識別とは、画像、音声、テキストなど入力されたデータを理解することができる機能であり、予測とは、得られたデータから予測・推論することができる機能を指す。最後に、実行とは、コンテンツの生成や行動の最適化など作業を担うことができる機能を指す。
AIにおける代表的なリスク
AIにおける代表的なリスクには、バイアス(偏見)を含んだ学習データ、説明できないアルゴリズム、プロンプトインジェクション、逆解析によるデータ漏えい、フェイク生成、詐欺、偽情報拡散、知的財産権関連(著作権など)、名誉毀損・プライバシー侵害・侮辱、倫理的なリスクなどが含まれる。
◆ バイアス(偏見)を含んだ学習データ
AIは社会にある膨大なデータから情報を学習することができるが、その際に差別的な内容や偏った情報も同時に学習してしまう可能性がある。差別的な内容の善悪はAIには判断が付かないため、非倫理的な内容は人権侵害や差別の拡大といった被害を生み出してしまうというリスクが存在する。
◆ ハルシネーション
AIの学習データに誤りがあったり、情報の文脈理解が不足したりすることで、AIが実際には存在しない情報を事実のように生成することがある。ハルシネーションはAI技術の信頼性に関わる大きな課題であり、対策として学習データの質の向上や人間によるフィードバックが重要であると言われている。

◆ プロンプトインジェクション
悪意のあるプロンプト(AIへの命令)が仕込まれ、意図しない情報漏えいや誤動作を引き起こすことが考えられる。例えば「機密情報を教えて」や「ハッキングをして」といった不正なプロンプトに対して、AIが実行してしまう可能性が考えられる。特定の個人だけでなく攻撃先に選ばれた組織や社会全体が被害を受ける可能性がある。開発時に不備があったり、管理体制が整備されてない場合には、開発したその組織にも責任が及ぶ可能性がある。
◆ 知的財産権関連(著作権など)
画像、文章、音楽などAIにより生成したものが著作権を侵害するケースなどが考えられる。また、このリスクは権利者であるクリエイターが直接の被害を受けるが、著作権を侵害した者にも、賠償責任や訴訟リスクが発生することが考えられる。
◆ 逆解析によるデータ漏えい
AIモデルの挙動を分析することで、学習データに含まれる情報などが特定され悪用されることが考えられる。特にAIの学習に誤って個人情報を使用していた場合などはそのリスクが高まり、開発者にも責任が及ぶ場合がある。これにより、本来守られるべきプライバシーが侵害される恐れがある。
◆ フェイク生成、詐欺、偽情報拡散
AIによって偽の画像・文章・動画を生成し、詐欺行為や世論操作に利用されることが考えられる。例えば偽のニュース記事などが拡散されると、社会的混乱や名誉毀損が発生する。この場合、被害を受けるのは個人の名誉毀損だけでなく、社会全体への影響(誤情報による混乱)も含まれる。
◆ 名誉毀損やプライバシー侵害
他人の顔を使いディープフェイク(AIによって生成された画像や音声、動画)を生成した場合、名誉毀損となる可能性がある。また、リアリティのある虚偽の情報は社会全体への混乱を招く恐れがある。例えば、選挙期間中に特定の候補者の誤情報を流すなど行った場合には、公職選挙法などにも抵触する可能性がある。
◆ 倫理的なリスク
倫理的なリスクには、倫理配慮不足が起因するものが考えられる。法的には問題がない場合でも、AIが生成したコンテンツなど倫理に反する内容が出力される可能性がある。この場合、利用者だけでなく、閲覧者や無関係な第三者が心理的被害を受ける可能性があり、企業の社会的信用を大きく損なうことも考えられる。なお、倫理的に問題がある内容には、以下のようなものが考えられる。
■ 暴力的な内容(犯罪の計画や危険物の作成方法など)
■ 性的なコンテンツ(性的な内容を連想させる画像や動画など)
■ 差別的な内容(マイノリティを蔑むような文章など)